Understanding Large Social Networks
Base paper: LINE: LARGE-SCALE INFORMATION NETWORK EMBEDDING

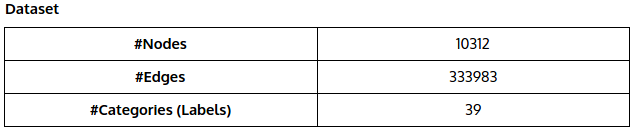
Information networks are ubiquitous in the real world with examples such as airline networks, publication networks, social and communication networks, and the World Wide Web. The size of these information networks ranges from hundreds of nodes to millions and billions of nodes.
We will be working on the problem of embedding information networks into low-dimensional spaces, in which every vertex is represented as a low-dimensional vector. Such a low-dimensional embedding is very useful in a variety of applications such as visualization, node classification, link prediction and recommendation.
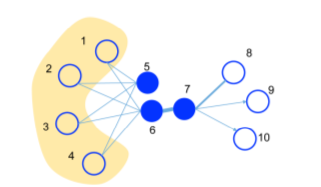

The First-order proximity refers to the local pairwise proximity between the vertices in the network (only neighbours).

Second-order proximity checks for directly connected nodes as well as other nodes which have influence over itself.

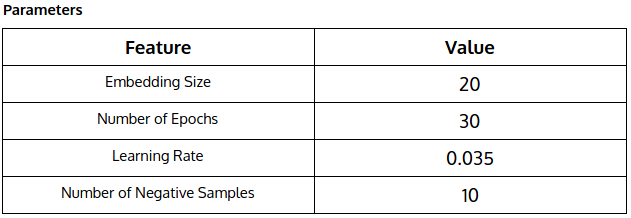
Negative Sampling, which samples multiple negative edges according to some noisy distribution for each edge (i, j).